Recent research suggested that the embeddings produced by CLIP-like contrastive language-image training are suboptimal for image-only tasks. The main theory is that the inter-modal (language-image) alignment loss ignores intra-modal (image-image) alignment, leading to poorly calibrated distances between images. [1,2,3]
TL;DR
Are CLIP and SigLIP really “intra-modally misaligned”?
We find little support for it.
Abstract
What is the "Intra-Modal Misalignment Hypothesis"?
What is our "Reevaluation"?
In this study, we question this intra-modal misalignment hypothesis.
We reexamine its foundational theoretical argument, the indicators used to support it, and the performance metrics affected. For the theoretical argument, we demonstrate that there are no such supposed degrees of freedom for image embedding distances. For the empirical measures, our findings reveal they yield similar results for language-image trained models (CLIP, SigLIP) and image-image trained models (DINO, SigLIP2). This indicates the observed phenomena do not stem from a misalignment of the former. Experiments on the commonly studied intra-modal tasks retrieval and few-shot classification confirm that addressing task ambiguity, not supposed misalignment, is key for best performance.
The Reevaluation
Previous Concern (Fig. 4a-c)

Two image embeddings with same distance $r$ to a text embedding...
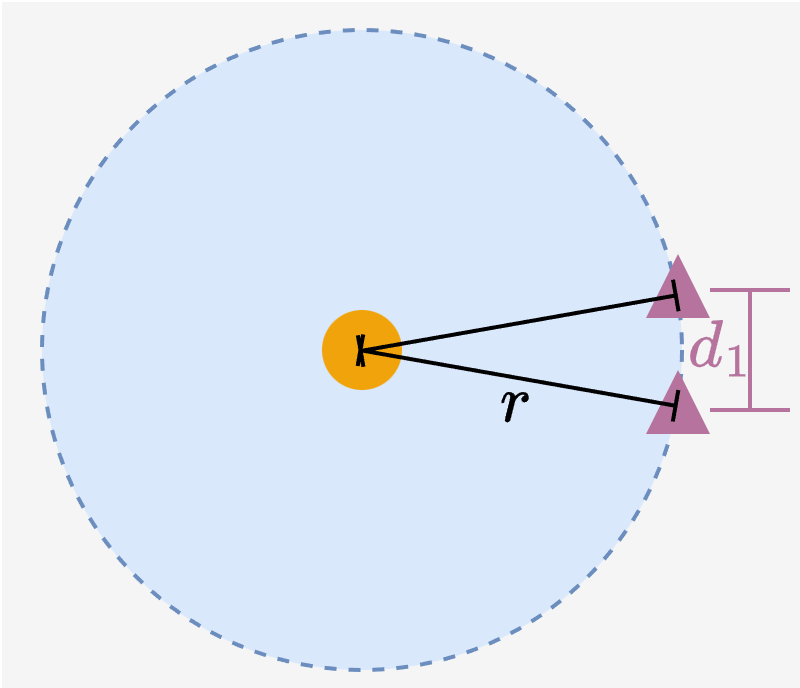
(a) ...can be close together
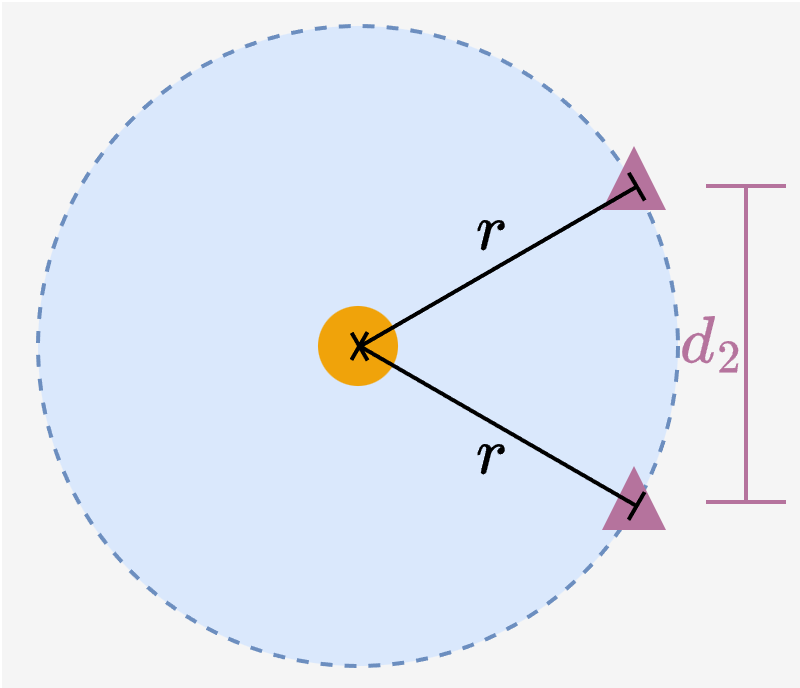
(b) ... or far apart
(c) Previous conclusion: a degree of freedom remains → image-image misalignment possible.
Image embeddings can lie on any arbitrary points on the circumference, leaving a degree of freedom for intra-modal miscalibration.
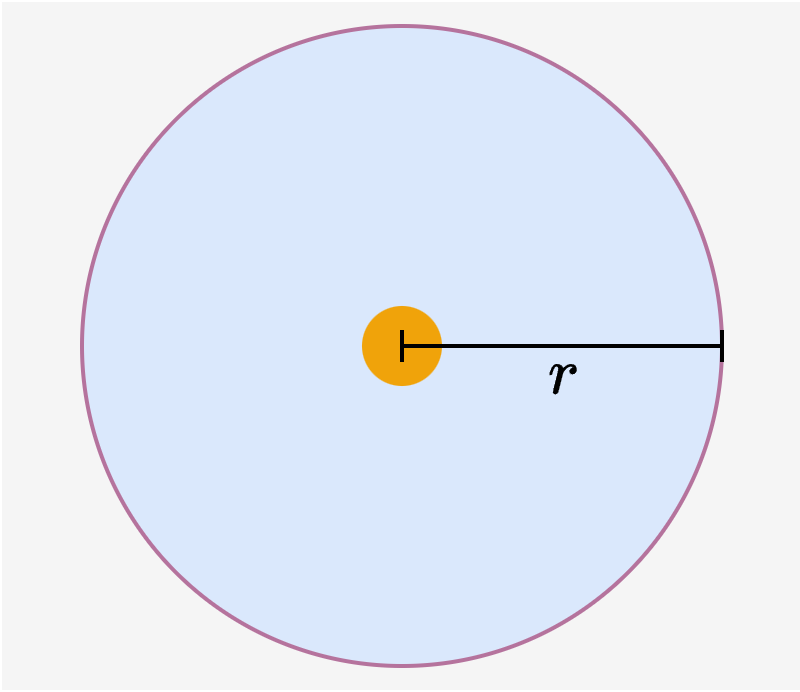
Our Explanation (Fig. 4d-f)

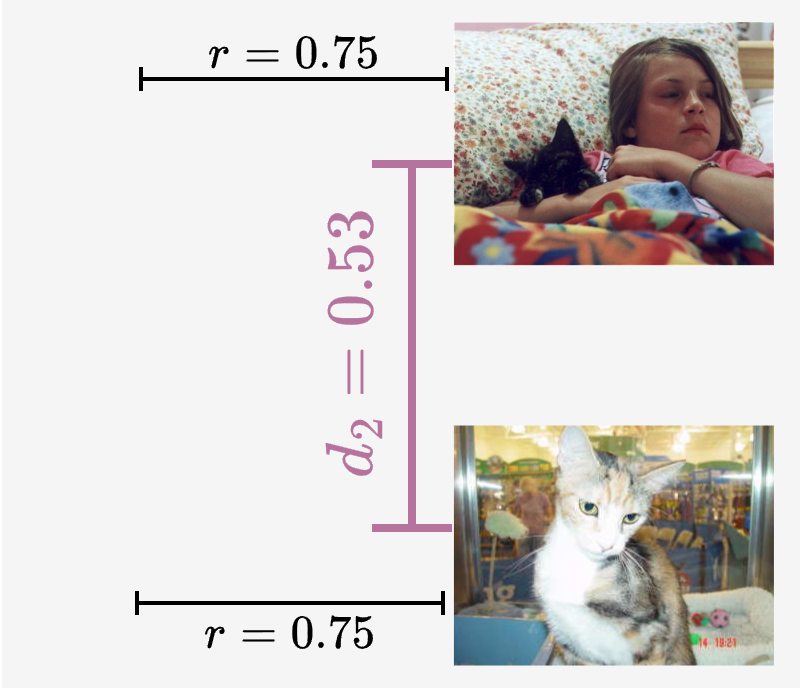
(d,e) The two different configurations in (a) and (b) are not arbitrary, but have a good reason to exist: Images in (a,d) and (b,e) have equal distance \(r\) to the "cat" text, but the two images in (a,d) are much more similar to each other than those in (b,e). Displayed distance values are real measurements.
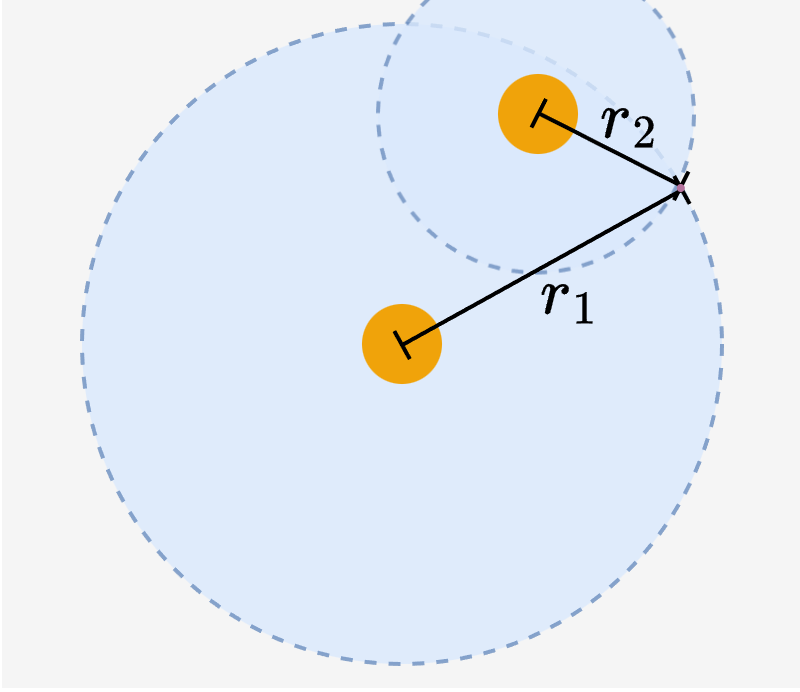
(f) Intra‑modal similarities are a consequence of inter‑modal similarities – no extra degree of freedom. The previous line of argumentation overlooks that each image embedding is bound to more than one text after training.
@@
Previous Concern (Fig. 2)
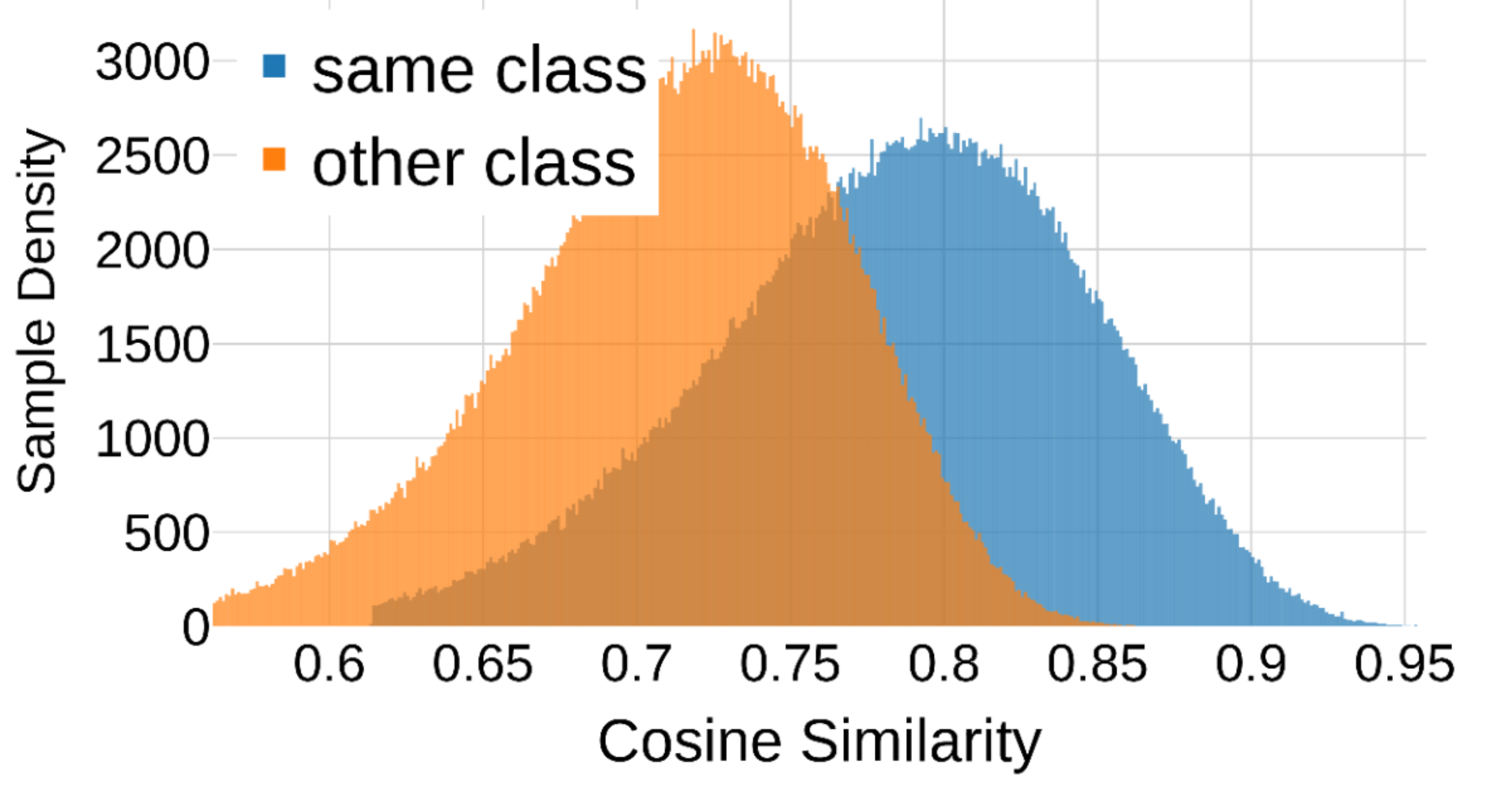
Figure 2 (by class). Pairwise cosine similarity distributions. Similarities between same class (blue) and opposite class (orange) image feature pairs. A high overlap ratio between the two colors was previously highlighted as an indicator for an intra-modal misalignment issue in CLIP.
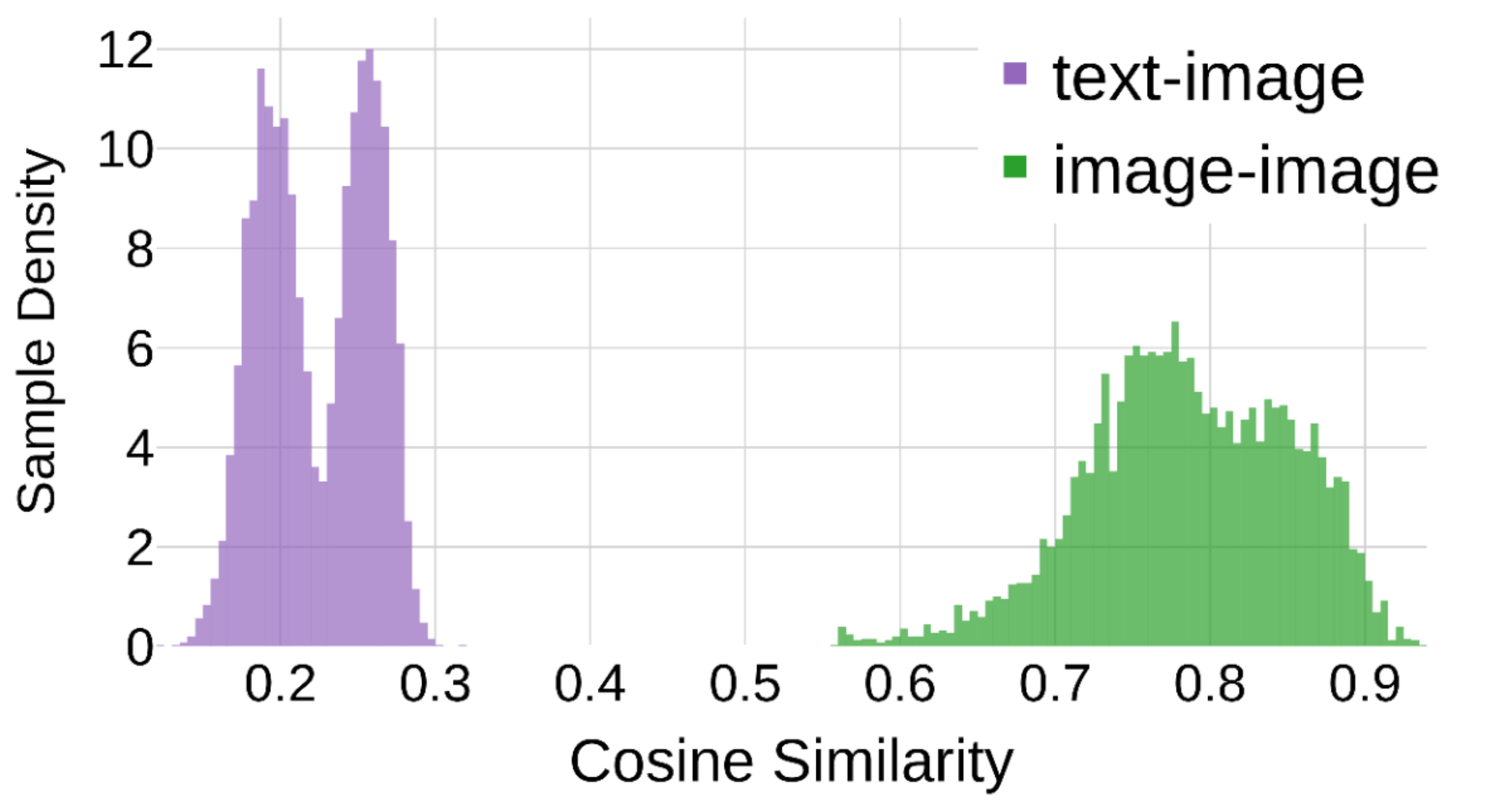
Figure 2 (by modality). Similarity distributions of image-text pairs (purple) versus image-image pairs (green). Because CLIP is only supervised on the former, the divergence has previously prompted concerns about whether the latter reflect true similarities.
Our Finding (Fig. 5)
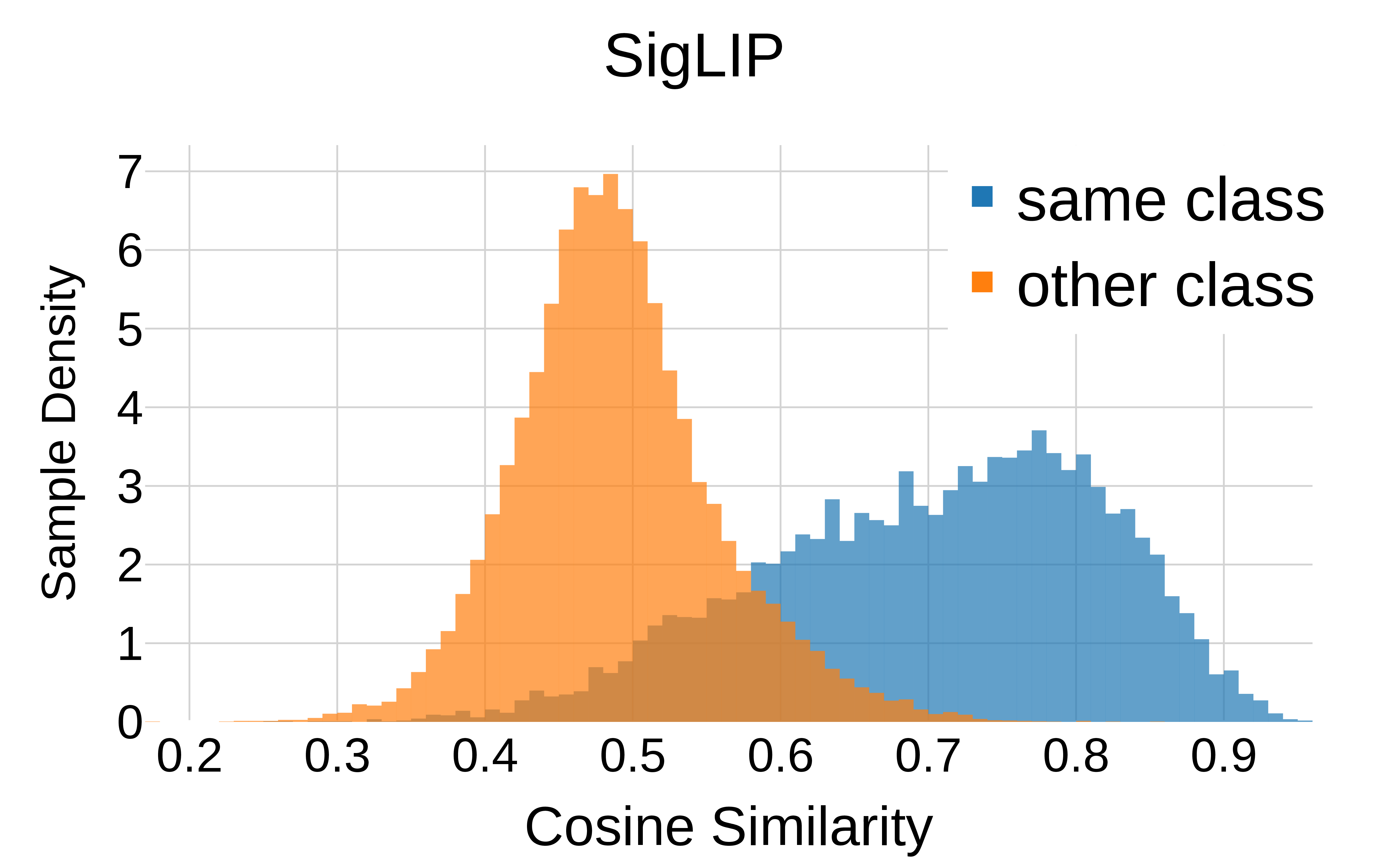
SigLIP (inter-modal only)
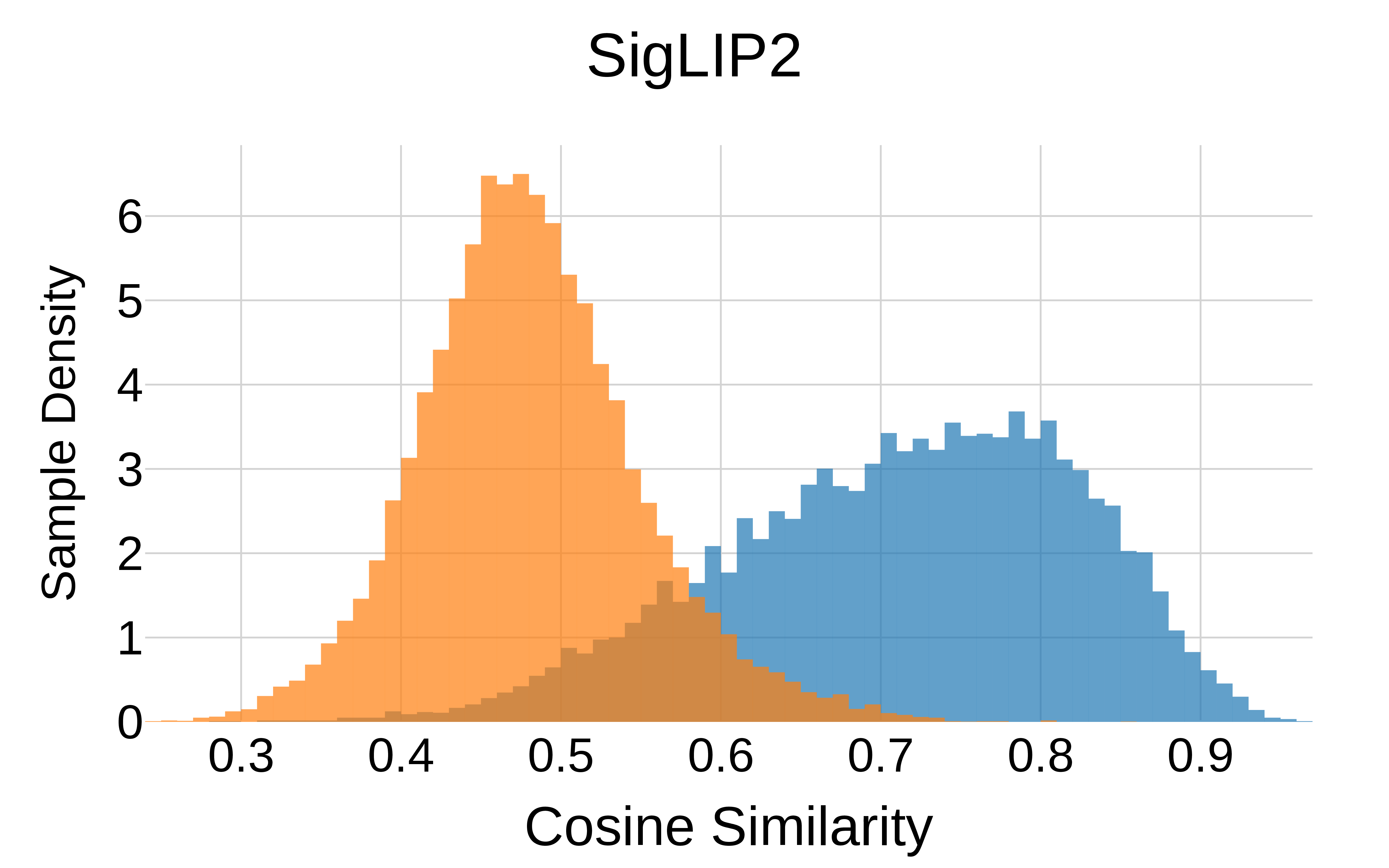
SigLIP2 (with intra-modal objective)
Figure 5 (by class). Cosine similarity histograms by class. The distributions are almost equal for purely text-image trained SigLIP (left) and SigLIP2 (right) which includes an image-image self-supervised objective as in the DINO line of work. This indicates intra-class variation is no sign of misalignment brought by pure text-image training, but rather normal behavior.
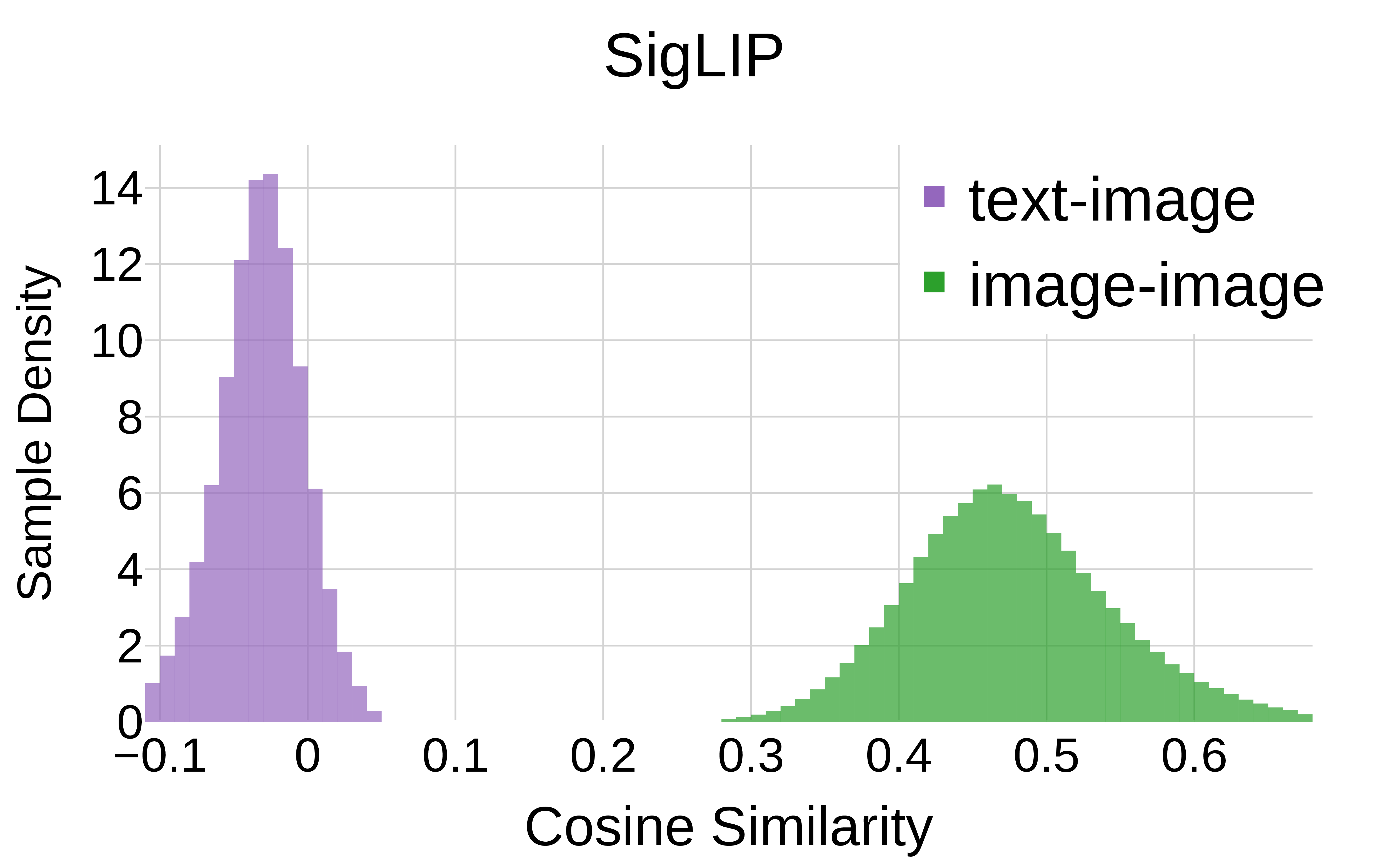
SigLIP (inter-modal only)
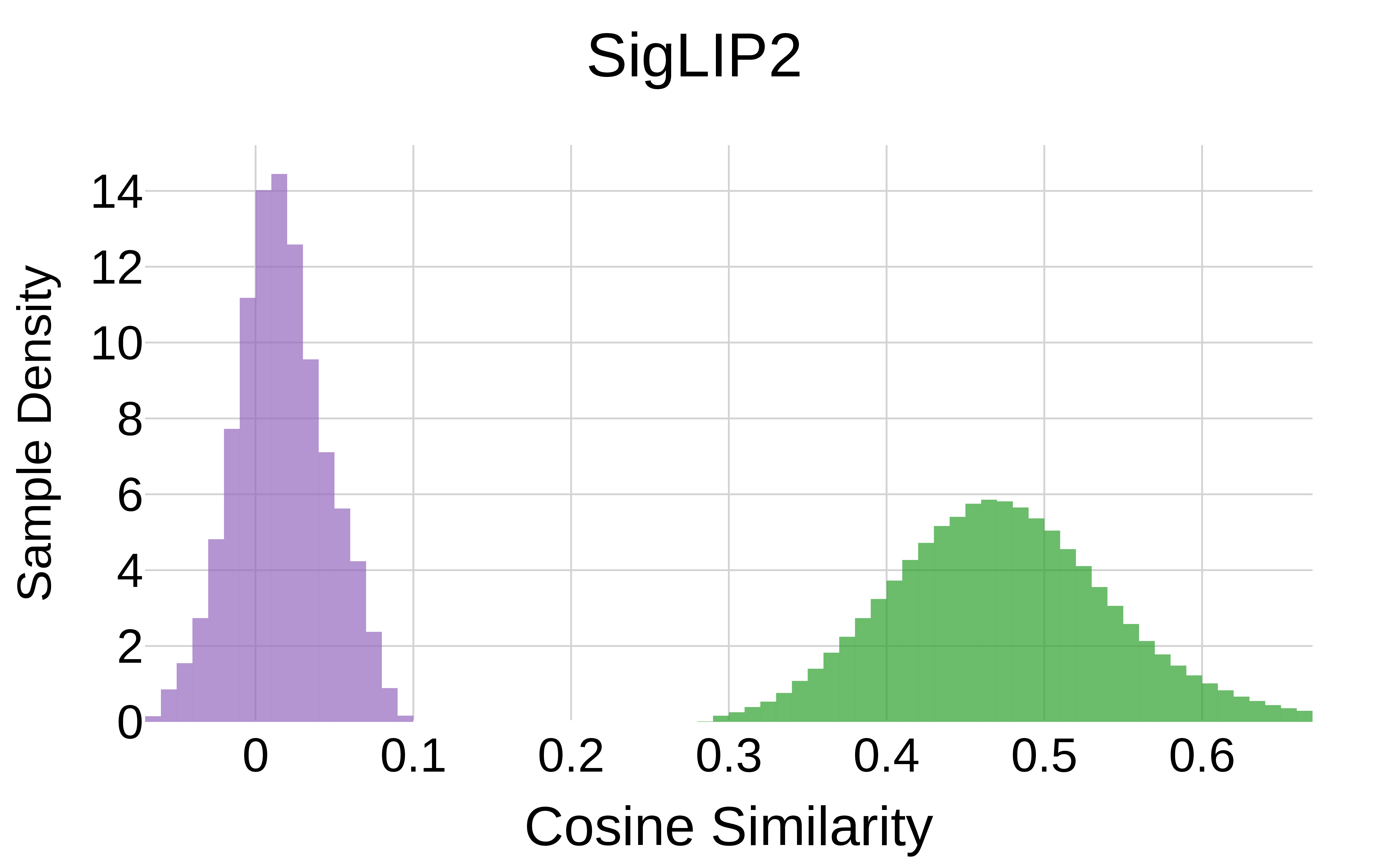
SigLIP2 (with intra-modal objective)
Figure 5 (by modality). Cosine similarity histograms by modality. The divergence in similarity distributions between inter-modal (image-text) and intra-modal (image-image) pairs is nearly identical for both models. The fact that SigLIP2's additional image-image training does not close this gap demonstrates this is not a misalignment introduced by a missing image-image objective.
@@
Questioning Few-Shot Metrics on Toy Dataset
Table 1. Repeating the demonstrative experiment in [1] on the simplistic Dogs vs Cats legacy dataset, where near-perfect results are expected. It was suggested in [1] that poor results with CLIP image-image similarities evidences a misalignment in the image-image space. This hypothesis gets no evidence when swapping model for the uni-modal DINO, a widely acknowledged state-of-the-art image embedder. CLIP scores highest, suggesting that the observed low metrics are not caused by a model weakness and hence neither by a misalignment. Instead, the performance gap between text-image (T-I) and image-image (I-I) can be attributed to the ambiguity in the way the task is conveyed to the model: Two images with opposite labels might still share enough other concepts to be justifiably similar.
| Model | Retrieval (mAP) | Classification (acc.) | ||
|---|---|---|---|---|
| T‑I | I‑I | T‑I (0‑shot) | I‑I (1|16‑shot) | |
| CLIP ViT‑B/16 | 99.3 | 87.1 | 99.6 | 84.2 | 99.7 |
| DINOv2 ViT‑B/14 | – | 81.8 | – | 76.2 | 97.3 |
| DINOv3 ViT‑L/16 | – | 84.3 | – | 80.2 | 97.8 |
Reevaluating Image-to-Image Few‑shot Classification
Table 2. SigLIP (inter‑modal only) outperforms DINOv2, showing no disadvantage from missing intra‑modal loss.
| Model | 2‑shot | 4‑shot | 8‑shot | 16‑shot | ||||
|---|---|---|---|---|---|---|---|---|
| Proto | LDA | Proto | LDA | Proto | LDA | Proto | LDA | |
| CLIP ViT‑B/16 | 55.3 | 60.0 | 63.8 | 69.8 | 69.6 | 76.1 | 73.5 | 79.5 |
| SigLIP ViT‑B/16 | 68.6 | 71.0 | 76.3 | 79.0 | 80.5 | 83.3 | 82.5 | 85.3 |
| SigLIP2 ViT‑B/16 | 69.7 | 73.2 | 77.0 | 80.5 | 80.8 | 84.5 | 83.0 | 86.5 |
| DINOv2 ViT‑B/14 | 67.1 | 69.2 | 71.8 | 75.3 | 76.0 | 80.3 | 78.2 | 83.3 |
Reevaluating Image‑to‑Image Retrieval
Table 3. Simple $PCA^\leftarrow$ consistently outperforms Optimization-based Textual Inversion (OTI) – no need to convert images to pseudo-text tokens to “fix” a misalignment.
| Model | Method | Average | ROxford | RParis | Caltech101 | DTD | EuroSAT | FGVCAircraft | Flowers102 | Food101 | ImageNet | OxfordPets | StanfordCars | SUN397 | UCF101 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CLIP B/32 | Original | 41.6 | 42.4 | 74.0 | 77.7 | 28.3 | 49.3 | 14.5 | 62.5 | 33.6 | 21.6 | 31.2 | 24.9 | 34.6 | 46.2 |
| -- OTI | 42.9 | 43.0 | 70.3 | 79.9 | 31.9 | 47.2 | 14.4 | 62.6 | 34.7 | 23.8 | 37.5 | 28.0 | 36.3 | 48.6 | |
| ++ PCA← | 49.0 | 51.4 | 80.9 | 83.3 | 34.0 | 53.8 | 16.1 | 70.3 | 43.0 | 28.6 | 47.7 | 34.6 | 40.0 | 53.3 | |
| CLIP L/14 | Original | 53.7 | 57.1 | 77.8 | 83.8 | 33.9 | 57.8 | 25.8 | 84.2 | 55.0 | 33.0 | 47.2 | 43.8 | 39.2 | 59.5 |
| -- OTI | 57.0 | 62.4 | 77.1 | 87.3 | 37.7 | 56.3 | 27.1 | 86.0 | 55.9 | 38.2 | 56.0 | 50.5 | 43.5 | 62.8 | |
| ++ PCA← | 61.3 | 64.5 | 83.0 | 89.5 | 39.9 | 62.8 | 28.7 | 88.9 | 64.4 | 42.2 | 62.7 | 57.2 | 46.0 | 66.8 | |
| SigLIP B/16 | Original | 57.2 | 50.6 | 73.1 | 87.2 | 39.8 | 53.3 | 37.9 | 87.5 | 56.3 | 35.8 | 56.4 | 65.7 | 42.8 | 56.9 |
| -- OTI | 60.0 | 55.2 | 79.1 | 88.9 | 43.3 | 52.9 | 37.6 | 89.7 | 59.0 | 38.8 | 64.2 | 71.8 | 43.6 | 54.9 | |
| ++ PCA← | 62.8 | 57.9 | 78.4 | 91.2 | 44.2 | 54.2 | 40.9 | 92.0 | 61.8 | 43.5 | 68.5 | 77.2 | 46.9 | 60.3 | |
| SigLIP2 B/16 | Original | 58.6 | 52.5 | 75.6 | 89.2 | 38.6 | 49.3 | 40.7 | 89.3 | 59.7 | 37.9 | 56.6 | 70.8 | 43.0 | 59.2 |
| ++ PCA← | 64.4 | 59.4 | 78.6 | 93.0 | 44.1 | 51.1 | 46.3 | 93.2 | 65.3 | 46.5 | 67.8 | 80.2 | 48.9 | 63.0 |
[1] Mistretta et al.: "Cross the gap: Exposing the intra-modal misalignment in clip via modality inversion", ICLR 2025.
[2] Yi et al.: "Leveraging cross-modal neighbor representation for improved clip classification", CVPR 2024.
[3] Udandarao et al.: "Training-free name-only transfer of vision-language models", CVPR 2023.
Code
Projection Minimal Example Modify any image embedding to get the \(PCA^\leftarrow\) results from the paper.
import requests
import torch
import torch.nn.functional as F
import clip # pip install git+https://github.com/openai/CLIP.git
clip_model, preprocess = clip.load("ViT-B/16")
# 1. Get ImageNet class names
response = requests.get('https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt')
class_names = response.text.strip().split('\n')
# 2. Get text features of class names
tokenized = clip.tokenize(class_names)
with torch.no_grad():
text_embeds = F.normalize(clip_model.encode_text(tokenized), dim=1)
d = text_embeds.shape[1]
# 3. Get principal components
U,S,Vt = torch.linalg.svd(text_embeds.float())
selected_components = Vt[:d//2] # keep d/2 (e.g. 256 of 512)
# 4. Now you can project any image embeddings
image_embeddings = torch.randn(100, 512) # replace with clip_model.encode_image(...)
image_embeddings_proj = image_embeddings @ selected_components.T
print(image_embeddings_proj.shape) # (100, 256)Drop-in projection class: span_projection.py
Intra-Modal Similarity Recovery Recover image-image similarities given only text-image similarities (Appendix A).
import torch
import torch.nn.functional as F
N, d = 42, 3 # set number of embeddings (N) and their dimension (d)
# Setup
X_T = F.normalize(torch.rand(N,d),dim=1) # text embeddings, hidden
X_I = F.normalize(torch.rand(N,d),dim=1) # image embeddings, hidden
S_inter = X_T @ X_I.T # text-image similarities, given
# Decompose
U, Sigma, Vt = torch.linalg.svd(S_inter)
U, V = U[:,:d], Vt.T[:,:d] # reduced SVD (rank d)
pairwise_products = V.unsqueeze(2) * V.unsqueeze(1)
# Solve
A = pairwise_products.view(N,d*d)
b = torch.ones(N)
x = torch.linalg.lstsq(A, b, driver='gelsd').solution
# Recover
Q = x.view(d,d)
S_intra_recovered = V @ Q @ V.T
# Check
S_intra_true = X_I @ X_I.T
print('RESULT: recovery error:', (S_intra_recovered - S_intra_true).abs().max())Full annotated walkthrough: s_intra_recovery.py
Ask your agent:
I want to try [the PCA projection from this paper]. Pull it from https://github.com/Vision-Kek/Is-CLIP-Really-Misaligned.Take Home Messages
Image-image distances are constrained
After training, if text-image similarities are well-calibrated, then image-image similarities are well-defined too. This is like an overconstrained bipartite graph.
No difference with or without intra-modal loss
We didn't find significant differences between models with and without an intra-modal training objective. So we have no reason to believe that a missing intra-modal objective causes intra-modal misalignment.
Basic few-shot methods are competitive
Classic ML techniques like linear discriminant analysis (LDA) work quite well on raw image embeddings. No specialized fix for "misalignment" is needed.
Dropping class-irrelevant information explains and exceeds previous results
Removing visual details from the embedding removes information spurious w.r.t. the class label, mitigating task ambiguity in the few-shot setting. This is what our $PCA^\leftarrow$ does — and why some previous attempts worked.
Cite this work
@article{herzog2026reevaluating,
title = {Reevaluating the Intra-Modal Misalignment Hypothesis in CLIP},
author = {Jonas Herzog and Yue Wang},
journal = {arXiv preprint arXiv:2603.16100},
year = {2026}
}